



学習による誤変換を防ぐアルゴリズム
新エンジンでは、変換強度を弱めて誤変換を防ぐアルゴリズムとして、まずは、「個人による入力の特徴」に着目し、以下の2つの項目を備えました。
過去の入力内容と現在の入力状況を元に、後変換の強度を調整
ATOKには、カタカナ語等を簡単に入力するために「後変換」と呼ばれる機能が存在します。
例えば「とくしま」と入力してF7キーを押すことで、「トクシマ」に変換できます。
後変換でカタカナ語を入力すると、以後同じ読みを入力し変換したときに、そのカタカナ語が優先して提示されるようになります。
しかし名前のフリガナを入力した場合など、常に後変換の結果を優先することが適切でないことも多々あります。
そこで、ユーザーの普段の入力内容と現在の入力状況から、後変換の強度を弱めるべきかどうか判断するようにし、
後変換の学習が弱められた場合、その読みを別のアプリで入力したときに、後変換の候補を優先しないようにしました。
たとえば・・・
 普段は、自分の名前を漢字で入力しています。
普段は、自分の名前を漢字で入力しています。
⇒ (ATOKの内部では・・・)
ある読み(今回の場合は自分の名前の読み)に対して、
特定の表記で多く確定していることを、ATOK内部で記憶しています。
普段は、メールや文書作成などで...



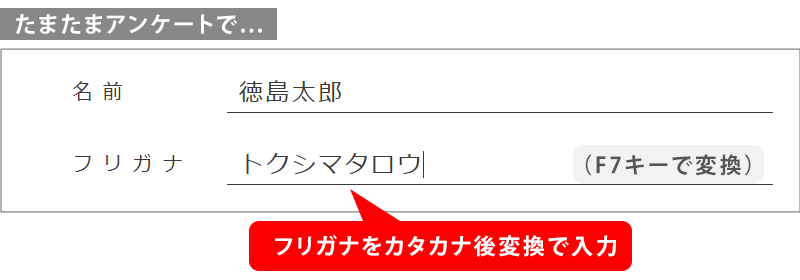
 今日、たまたま、アンケート等の入力欄で、漢字の姓名の直後にフリガナをカタカナ後変換で入力しました。
今日、たまたま、アンケート等の入力欄で、漢字の姓名の直後にフリガナをカタカナ後変換で入力しました。
⇒ (ATOKの内部では・・・)
今回も、自分の名前の読みに対してATOK内部で記憶された表記と同じ入力が行われたことを把握。
しかし同じ文脈で、それまで多く確定された表記と異なり、あまり確定されたことがない表記に後変換された場合に、その後変換結果での変換強度を低く学習すべきと判断します。
具体的には、漢字の名前やその他の文脈の構成語に対するカタカナ表記の出現確率を算出し、カタカナ表記の出現確率が十分に低い場合、その変換強度を弱く学習します。
 その後、別アプリで、名前の読みを入力しスペースキーで変換したとき、カタカナのフリガナにならず、いつも入力している漢字で名前が入力されました!
その後、別アプリで、名前の読みを入力しスペースキーで変換したとき、カタカナのフリガナにならず、いつも入力している漢字で名前が入力されました!
⇒ (ATOKの内部では・・・)
従来は、ユーザーの学習結果を優先して後変換結果を提示することが多くありました。
本アルゴリズムでは、弱く学習された結果は優先せず、次点(今回の場合は漢字表記)の候補を提示するようになります。
過去の入力内容と現在の入力状況を元に、スペース変換の強度を調整
スペースキーによる変換時においても、過去の入力内容と現在の入力状況から変換の強度を判断します。
学習が弱められた場合、その後同じ読みを入力したときに、学習された候補を優先しないようにします。
たとえば・・・
普段は、「しんせいまち」は「申請待ち」と変換しています。
⇒ (ATOKの内部では・・・)
ある読みに対する特定の表記が、特定の単語と同じ文脈内で多く確定されていることをATOK内部に記憶します。
今回の場合、「しんせいまち」の読みに対して「申請待ち」の表記が、「システム」「申し込み」などの単語とともに確定されていることをATOKが記憶しています。
普段は、「申請待ち」と入力...



昨日、たまたま、「新生町」の候補を選択して確定しました。
⇒ (ATOKの内部では・・・)
今回も「システム」「申し込み」などの文脈を入力したが、
「しんせいまち」の読みに対して
「新生町」という表記に次候補選択して確定しました。
「新生町」という表記は、この文脈で「しんせいまち」という読みに対して
普段入力しているものと異なる、とATOKが判断。
具体的には、文脈の構成語に対して、
ATOKが記憶している表記と今回確定した表記との出現確率をそれぞれ統計的なアルゴリズムにより算出。
今回確定した表記の出現確率のほうが十分に低い場合に、低い変換強度で学習します。

その後の入力で、誤変換にならない。
⇒ (ATOKの内部では・・・)
以後、同じ文脈で「しんせいまち」と入力し変換したとき、
低い変換強度で学習した「新生町」ではなく、次点の「申請待ち」の候補を優先して提示します。
ATOKでは常に変換の精度を高めるための努力を続けています。今回は特に、文章を学習する機能に注目しました。
人間が書く文章は、例えば「文法」と呼ばれる基本的なルールに従ってはいるものの、例外も多いため、予想外の問題が発生することもあります。
例えば、変換の精度を上げるために行った対応が、逆に誤った変換結果を生むこともありました。
これを防ぐために、人間であれば何年もかかって入力するような大量の文章を実際に変換させて、その結果を確認しました。
変換がうまくいかない部分が見つかるたびに、微調整を繰り返しました。
その結果、誤変換を最小限に抑えながら、できるだけ多くの改善効果が得られるようになっています。
このような地道な取り組みの積み重ねが、ATOKの変換性能を支えています。
ATOKはお客様にとって使いやすい日本語入力システムを提供するために、これからも改善を続けていきます。

ATOK開発チーム、変換エンジン開発担当のK.Tです。
ATOKの変換エンジンは、お客様が選択し確定した変換候補を尊重し、優先する設計になっています。
学習結果が即座に次回の変換で反映されることは、多くのお客様から評価いただいている点でもあります。
ただ、直前に学習したものを優先しすぎることで、事例によっては「いま変換したいのはこれではない」という結果になることもあります。
例えば開発者である私自身も、自分の名前を変換した際に以前に入力したフリガナが影響してカタカナになり、がっかりすることがありました。
ATOKの進化の方向性として学習に関しても、より「わたしの入力に沿う」形にする必要性を感じていました。
この課題を解決するために、ハイパーハイブリッドエンジンの技術を学習機能にも適用しました。
これにより、お客様の入力状況に応じて学習が最適化され、日本語入力がさらにスムーズになりました。
新しくなったATOKをぜひご体験ください!