




学習による誤変換を防ぐアルゴリズム
新エンジンでは、変換強度を弱めて誤変換を防ぐアルゴリズムとして、まずは、「日本語の特徴」に着目し、以下の2つの項目を備えました。
一時的に入力されることが多い低頻度語(町域名など)
日本語文書中での出現の特徴を元に、一時的に入力されることが多く、相対的に頻度の低い語(例えば町域名等の地名)について、
変換強度を弱めて学習用辞書に記録します。
これにより、別の文章を入力した際に、学習による誤変換を生じることを防ぎます。
たとえば・・・
 「中出(なかで)」という町域名を学習した場合
「中出(なかで)」という町域名を学習した場合
今までは、別の文章を入力した場合にも、「中出」が優先され、ユーザーの意図と異なる変換になることがありました。
⇒ 新エンジンでは、利用頻度が低いと判断された「中出」の変換強度を弱めることで、
「中で」という意図した候補を提示できるようになります。
▽ 出現確率(出現頻度イメージ)
| 中出 | 30 | ← 利用頻度が低いとみなして、変換強度を弱める |
|---|---|---|
| 中で | 120,000 |
▽ 例:
| 京都にある、中出という地域で生まれた。 |
|---|
| ×都会で就職し、日々の生活を送る中出、時折ふるさとを思い出すことがある。 |
| ○都会で就職し、日々の生活を送る中で、時折ふるさとを思い出すことがある。 |
 語の出現確率を、変換強度を弱めて次回以降の誤変換を防ぐ目的で利用します。
語の出現確率を、変換強度を弱めて次回以降の誤変換を防ぐ目的で利用します。
読みと品詞の並びから推定される、自然な日本語を優先
日本語文書中での利用頻度が「非常に低い」場合は、03の手法で変換強度を弱めることができますが、利用頻度は中程度にあり、一律変換強度を弱めてよいわけではないものも存在します。
そのような場合は、読みと品詞の並びから、より日本語として優先すべき候補がないかを探し、両者を比較することで適切な候補を提示することができます。
たとえば・・・
「有里(あり)」という人名を学習した場合
今までは、別の文章を入力した場合にも、「有里」が優先され、ユーザーの意図と異なる変換になることがありました。
⇒ 新エンジンでは、"こと(名詞)+も(助詞)の後に出現する「あり」は、動詞の「ある」が優先"というルールと比較して評価することで、適切な候補を提示することができるようになります。
▽ 出現確率(出現頻度イメージ)
| 有里 | 20,000 | ← それなりに頻度があり、利用頻度だけでは変換強度を弱める判断ができない |
|---|---|---|
| あり | 500,000 |
"こと(名詞)+も(助詞)の後に出現する「あり」は、動詞の「ある」が優先"するルールと比較して評価。
▽ 例:
| 彼女の名前は田中有里といった。 |
|---|
| ×趣味が同じということも有里、休日は一緒に美術館巡りをすることも多かった。 |
| ○趣味が同じということもあり、休日は一緒に美術館巡りをすることも多かった。 |
変換強度を弱めて、日本語として自然な別候補を提示します。
「ATOKハイパーハイブリッドエンジン2」の開発にあたり、開発者の考え方とか、ちょっとしたウラ話をご紹介して、
本記事を締めさせていただきます。
 学習とは
学習とは
例えば出荷状態のATOKで「しゅしょう」の読みを入力した際、「首相」「主将」「主唱」…の順で候補が並んでいるとします。
ここで変換キーを押すと、「首相」と変換されますが、候補ウィンドウから2番目以降の候補である「主将」を選択して確定した場合、学習が行われます。
この状態で再び「しゅしょう」と入力、変換した場合、「首相」ではなく、「主将」が第一候補として提示されます。
これは、第一候補である「首相」より「主将」を選んで確定したユーザーは、次回以降も「しゅしょう」の読みで「主将」と入力したいシーンが多いだろうという考え方によります。
これを繰り返すことで、様々な読みにおける第1候補が、ユーザーがより入力しやすい候補に置き換えられ、意図した変換結果になると考えられます。
2番目の候補である「主将」を選択、確定
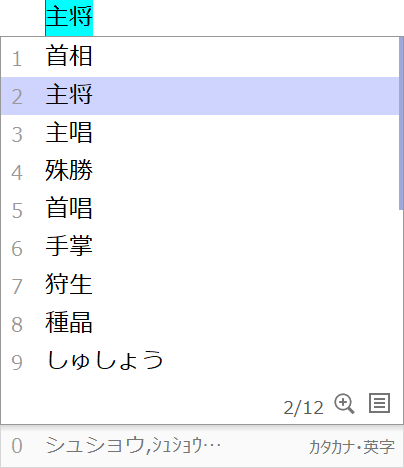
「しゅしょう」の読みで変換

 「確定した語をすぐに学習してくれる」とは
「確定した語をすぐに学習してくれる」とは
ATOKの特徴として、「確定した語をすぐに学習してくれ、次回の入力から変換に利用できる」というものがあります。
これは、ユーザーの確定した語を常に最優先で提示することで、一見簡単に実現できるように見えます。
しかし、確定した語を常に最優先で提示するとどうなるでしょうか。
例えば、「けっさい」の読みで、候補ウィンドウから「決裁」を選択し、確定した場合、「たっちけっさい」のときにも「タッチ決裁」の変換結果が出ると、意図した変換と異なる場合が多いでしょう。
このような誤変換を避けるために、ATOKは、「たっちけっさい」と入力されたら、ユーザーの「けっさい」における学習が「決裁」であっても、「タッチ決済」の候補を提示するという制御情報を持っています。
この情報は、AI変換と呼ばれ、ATOK8時代から現在に至るまでATOKの変換を支えてきた技術(*1)です。
(*1)最新のATOKでは、AI変換以外にも、この誤変換を防ぐための仕組みが多数搭載されています。
2番目の候補である「決裁」を選択、確定
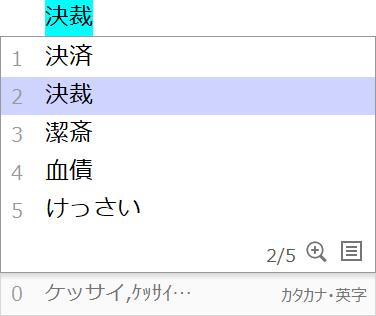
↓「決裁」の学習を覆して正しい候補を提示
○
×
日本語と40年以上向き合ってきたATOKだからできること
このように、
確定した語をすぐに学習して、次から変換に利用できるようにするためには、「学習によって語順が変わったとしても、誤変換を生じさせない仕組みを別途持つ」必要があることがわかります。
これは、ATOKが日本語と40年以上向き合ってきた中で、長年辞書データを蓄積し、エンジンを改良し続け、学習によって語順が変わっても意図した変換結果を得られるよう対応し続けてきたことで実現できたものです。
ユーザー独自の語が確定され、その語を使って以降の変換を実施しても、他の文脈への影響を最小限にして適切な候補を提示するための仕組みを備えているからこそ、「確定した語をすぐに学習してくれる」というATOKの特性を維持することができるのです。
「変換強度を制御する」新たなエンジンの開発
多くのユーザーに支持されるATOKの学習の特性を大切にしつつ、一部学習によって生じることのある誤変換にどのように対応するかは、長年の課題でした。
今回、ユーザーが確定した語について、一律に強く学習するのではなく、入力に応じて、強く学習する語、弱く学習する語を「自動判別する」という方法を取り入れることでこの課題を解決しました。
一般的には使用頻度が高くない語であっても、ユーザーの作成する文章の中では、創作物の主人公であったり、専門的な用語であったり、重要な語であることはしばしばあります。
同じ語であっても、ユーザーの入力によってその重要度が変わる、という点に着目し、今回ハイパーハイブリッドエンジン2として開発しました。
新しくなったATOKを是非お試しいただければと思います。

ATOK開発チーム、変換エンジン辞書開発担当のY.Wです。
ATOKは、日本語入力において意図した変換結果を得るため、実に40年以上にわたり、様々な機能追加と辞書情報の整備を行ってきました。
学習機能は、ユーザーの意図に沿う変換結果を提示するために、ATOKが初期の頃から備えている重要な機能です。
「入力した語をすぐに覚え、次回の入力からすぐに提示される」というATOKの快適な入力体験は、本機能によって支えられています。
このように強力な学習機能ですが、一部の入力において、意図した変換と異なる結果を提示する場合がありました。
例えば「三留」という人名を確定したあと、「~ことをみとめ」のように入力した際に、「~ことを三留」のように提示されてしまうことがありました。
この課題を解決するために、語そのものだけでなく、「~を+認め」のように前後に来る語とのつながりも含めたより詳細な情報を作成し、辞書に反映しました。
これにより、日本語として自然な文章がある場合は、直前に確定した語よりも、自然な文章の方を優先して提示できるようになりました。
ATOKにおける学習は、ユーザー辞書に蓄積されていきます。
学習はユーザーの入力したい語彙空間を記録する、ともに成長していく伴走者のようなものだと考えています。
様々な入力の選択肢がある中で、日本語入力にATOKが必要かと振り返ることもあるかと思いますが、わたし自身は、自分の入力に応じて素早く学習し、次回からの入力にすぐに使えるATOKを気に入って利用しています。
今回、新エンジンの搭載によって、快適な入力体験はそのままに、より賢くなったATOKを是非体感いただければと思います。